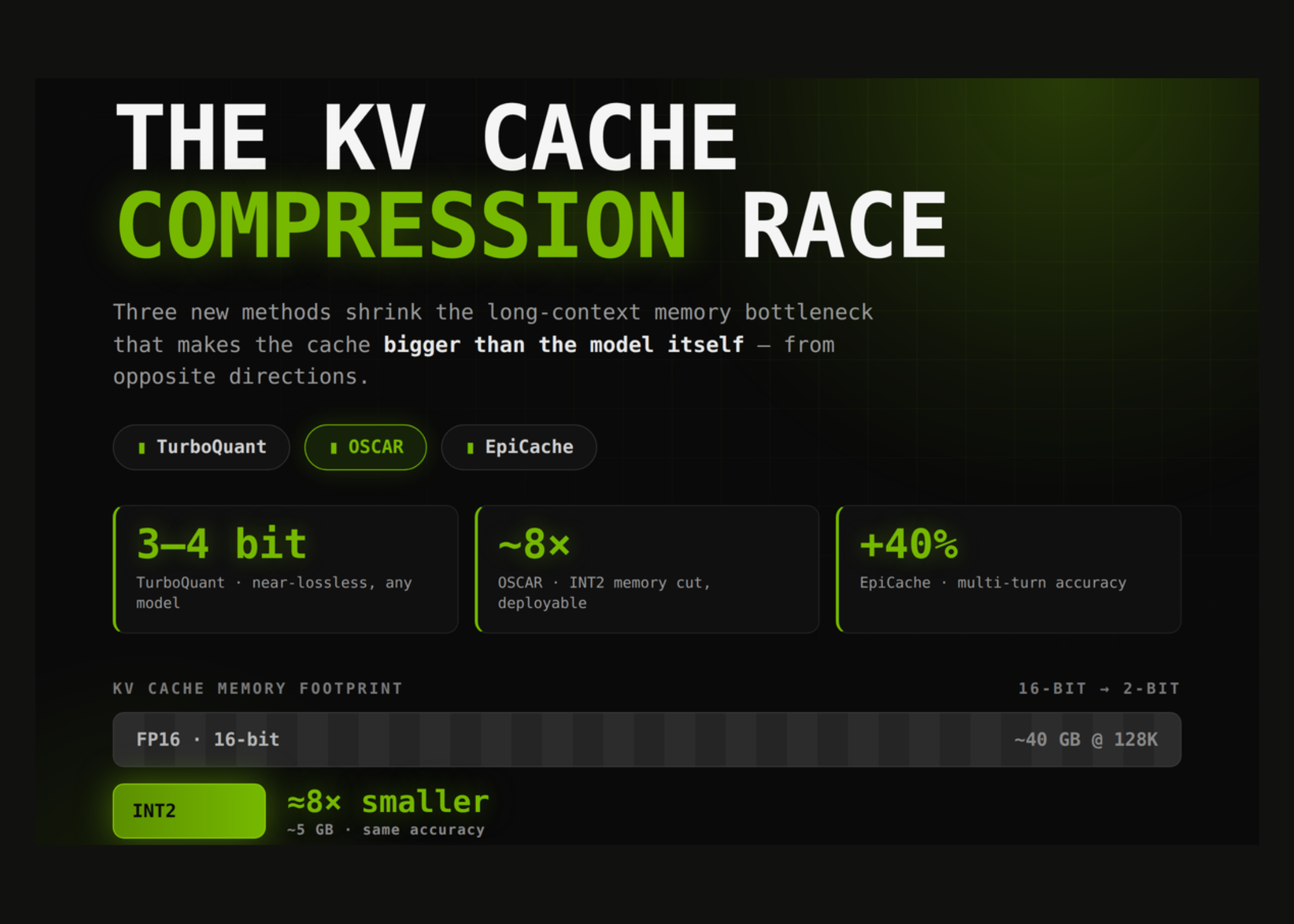
Corrida da Compressão KV Cache: TurboQuant vs OSCAR vs EpiCache

Modelos de linguagem grandes (LLMs) com contexto longo enfrentam um gargalo de memória que não tem nada a ver com os pesos do modelo. Durante a decodificação, os transformers armazenam em cache os vetores key e value (KV) de cada token em cada camada para evitar recomputar a atenção. Esse cache cresce linearmente com o comprimento da sequência e o tamanho do batch — em contextos longos com alta concorrência, ele pode superar o footprint do próprio modelo.
Considere o Llama-3.1-70B em BF16. Seu cache KV consome cerca de 0,31 MB por token. Em 128K tokens, isso representa aproximadamente 40 GB; em 1M tokens, ultrapassa 300 GB — mais que os 140 GB dos pesos do modelo. Pior: cada novo token decodificado precisa carregar todo o cache da memória de alta largura de banda (HBM), tornando a decodificação limitada pela largura de banda de memória, não pela computação.
Três métodos recentes de 2026 atacam esse problema de ângulos complementares: TurboQuant (Google/NYU), OSCAR (Together AI) e EpiCache (Apple).
TurboQuant: Teoricamente Ótimo e Agnóstico a Modelos
O TurboQuant lida com outliers sem nunca examinar os dados, em dois estágios:
- Estágio 1: cada vetor é rotacionado aleatoriamente para que suas coordenadas se tornem aproximadamente independentes e gaussianas, permitindo quantização escalar ótima (Lloyd-Max) por coordenada.
- Estágio 2: uma transformação Quantized Johnson-Lindenstrauss (QJL) de 1 bit é aplicada ao resíduo, produzindo uma estimativa não enviesada dos logits de atenção.
A distorção do TurboQuant é comprovadamente dentro de um fator constante (~2,7×) do limite inferior da teoria da informação. Na prática, atinge recall praticamente de precisão total no Needle-in-a-Haystack com compressão de 4×. Seu ponto ideal fica no regime de 3-4 bits com qualidade quase sem perdas. Por não precisar de calibração, funciona em qualquer modelo imediatamente.
OSCAR: INT2 Pronto para Produção
O OSCAR aposta na direção oposta. Sua premissa é que, com apenas 4 níveis do INT2, uma rotação cega não é suficiente. O OSCAR calcula uma rotação consciente da atenção a partir de uma calibração offline única:
- Chaves são rotacionadas para a base própria da covariância de queries.
- Valores são rotacionados para a covariância ponderada por score.
- Uma transformação Hadamard com permutação bit-reversal distribui a importância dos canais uniformemente.
O diferencial do OSCAR é ser um sistema completo: cache paginado de precisão mista (tokens recentes em BF16, histórico em INT2), kernels Triton fundidos com integração SGLang, e um "RotationZoo" com rotações pré-computadas para Qwen3, GLM-4 e MiniMax-M2.
Com 2,28 bits efetivos, o OSCAR fica a 1,42 pontos do BF16 no Qwen3-8B e praticamente empata no Qwen3-32B. A Together AI relata até 7,83× de throughput e ~8× de redução de memória em contexto de 100K, com decodificação até ~3× mais rápida.
EpiCache: Memória Conversacional
TurboQuant e OSCAR são otimizados para um único contexto longo. Nenhum lida bem com conversas multi-turno, onde o histórico se acumula através de várias trocas. O EpiCache da Apple ataca exatamente essa lacuna, com três inovações:
- Pré-preenchimento em blocos: processa o histórico em blocos para manter o pico de memória controlado.
- Agrupamento episódico: segmenta a conversa em "episódios" semânticos coerentes, cada um com seu próprio cache comprimido.
- Orçamento adaptativo por camada: mede a sensibilidade de cada camada à remoção e distribui o orçamento de memória de acordo.
Nos benchmarks LongMemEval, RealTalk e LoCoMo, o EpiCache reporta até 40% mais acurácia que baselines de evicção, precisão próxima ao cache completo com compressão de 4-6×, e até 3,5× menos pico de memória. Por decidir quais tokens manter (em vez de com que precisão armazená-los), ele se compõe diretamente com OSCAR ou TurboQuant para economias cumulativas.
Qual Escolher?
Nenhum vence em todos os cenários — e essa é a resposta honesta. A escolha depende da restrição:
- Orçamento de bits: TurboQuant para 3-4 bits near-lossless; OSCAR para INT2 extremo.
- Portabilidade de modelo: TurboQuant funciona em qualquer modelo sem calibração; OSCAR precisa de rotações pré-computadas.
- Conversas longas: EpiCache resolve o problema que os outros dois ignoram.
Essas abordagens são mais complementares do que competitivas. Combinar a rotação consciente de calibração do OSCAR com o quantizador escalar ótimo do TurboQuant é uma possibilidade promissora que nenhuma equipe publicou ainda — embora ambos os times tenham mencionado a ideia publicamente.
Fontes:
- TurboQuant: arXiv 2504.19874
- OSCAR: arXiv 2605.17757
- EpiCache: arXiv 2509.17396
Leia também

Reino Unido Vai Escanear Rostos de Solicitantes de Asilo para Verificação de Idade — Mesmo Sabendo que a Tecnologia É Falha
18 de junho de 2026
França Avança o Futuro da IA na Europa com Tecnologias NVIDIA
18 de junho de 2026
Midjourney revela scanner médico de corpo inteiro e anuncia spa de saúde em San Francisco
18 de junho de 2026