MiniMax lança MSA: atenção esparsa treinada em modelo de 109B parâmetros com 3 trilhões de tokens

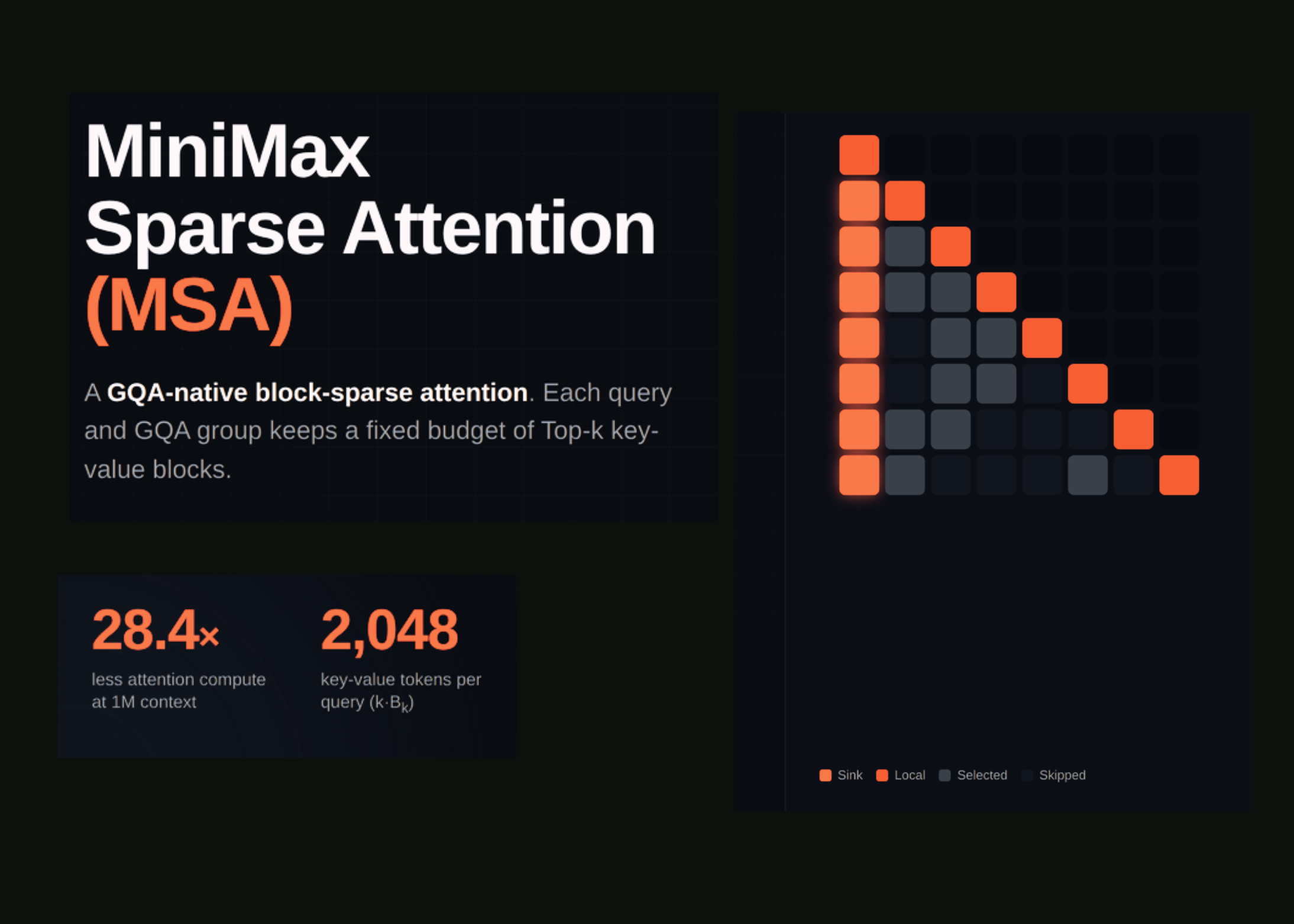
A MiniMax acaba de lançar o MSA (MiniMax Sparse Attention), um novo mecanismo de atenção esparsa que resolve um dos gargalos mais caros dos modelos de linguagem modernos: o custo quadrático da atenção softmax em contexto longo.
Testado dentro de um modelo Mixture-of-Experts de 109 bilhões de parâmetros treinado com dados multimodais nativos e um orçamento de 3 trilhões de tokens, o MSA consegue reduzir o custo computacional por token em 28,4× em contextos de 1 milhão de tokens. Em hardware real (NVIDIA H800), os ganhos chegam a 14,2× no prefill e 7,6× na decodificação.
Como funciona o MSA
O MSA divide a atenção em dois ramos:
-
Index Branch (Ramo de Indexação): decide quais blocos de chave-valor cada query deve ler. A seleção é feita em granularidade de bloco (128 tokens por bloco), e cada query mantém até 16 blocos — um orçamento fixo de 2.048 tokens de contexto, independentemente do tamanho total da entrada.
-
Main Branch (Ramo Principal): executa a atenção softmax exata apenas sobre os blocos selecionados pelo Index Branch. Como o orçamento é fixo, o custo não cresce com o contexto.
A seleção é compartilhada dentro de cada grupo GQA (Grouped Query Attention), mas independente entre grupos diferentes. Isso significa que diferentes grupos podem atender a regiões distintas de longo alcance — uma flexibilidade que métodos anteriores não ofereciam.
Treinamento com KL Divergence
O maior desafio técnico é que a seleção Top-k não é diferenciável, então o gradiente da perda de linguagem não consegue treinar o Index Branch. A equipe da MiniMax resolveu isso com uma perda de alinhamento KL: o Index Branch aprende a imitar a distribuição de atenção do Main Branch, como um aluno aprendendo com um professor.
Três mecanismos estabilizam o treinamento esparso:
1. Gradient Detach: o gradiente da perda KL não se propaga para o backbone do modelo, apenas para as projeções do indexador.
2. Indexer Warmup: nas primeiras iterações (40B tokens), ambos os ramos rodam atenção completa. O indexador aprende com a perda KL antes de começar a rotear de fato.
3. Local Block Forçado: um slot é sempre reservado para o bloco local da query, garantindo que o contexto imediato nunca seja descartado.
Resultados competitivos com atenção completa
Nos benchmarks, o MSA se mantém competitivo com o baseline de atenção completa:
| Benchmark | Full Attention | MSA-PT | MSA-CPT |
|---|---|---|---|
| MMLU | 67,0 | 67,2 | 66,8 |
| GSM8K | 76,2 | 77,7 | 73,7 |
| HumanEval | 61,0 | 64,0 | 57,9 |
| RULER-8K | 79,8 | 84,2 | 77,2 |
| RULER-32K | 75,0 | 77,5 | 75,7 |
O modelo suporta duas rotas de treinamento: MSA-PT (pré-treinamento do zero com warmup de 40B tokens) e MSA-CPT (conversão de um checkpoint denso de 2,6T tokens com mais 400B tokens de treino).
Kernel open source e MiniMax-M3
A MiniMax liberou o kernel de inferência sob licença MIT no repositório fmha_sm100, com suporte a BF16, FP8, NVFP4 e FP4. O kernel é otimizado para GPUs NVIDIA SM100, mas a arquitetura de dois ramos é genérica e pode ser adaptada para outras plataformas.
O MSA já está em produção no MiniMax-M3, o modelo multimodal mais recente da empresa, e foi otimizado para casos de uso que exigem contexto extremamente longo:
- Agentes de longa duração: centenas de etapas de raciocínio e ação acumulam transcrições enormes.
- Raciocínio sobre repositórios de código: um agente que carrega um repositório inteiro pode exceder centenas de milhares de tokens.
- Memória persistente: assistentes que mantêm estado conversacional crescente.
- Compreensão de vídeos longos: o modelo é nativamente multimodal e obteve as melhores pontuações em benchmarks como VideoMME.
Por que isso importa
A atenção esparsa não é uma ideia nova — DeepSeek (NSA), Microsoft (InfLLM-V2), MoBA e MiniMax (Lightning Indexer) já exploraram o conceito. Mas o MSA se destaca por três fatores:
- Granularidade de bloco por grupo GQA: cada grupo tem sua própria seleção, mantendo leituras KV contíguas e permitindo especialização.
- Co-design algoritmo-kernel: o kernel exp-free Top-k é 5,1× mais rápido que
torch.topkem contexto de 128K. - Código aberto e pronto para produção: kernel MIT, modelo em produção, treino documentado com orçamento de 3T tokens.
O paper completo está disponível no arXiv e o código no GitHub da MiniMax.
Para desenvolvedores e pesquisadores que trabalham com contextos longos, o MSA representa um avanço significativo: prova que é possível treinar atenção esparsa nativamente, mantendo qualidade competitiva com atenção densa, sem os truques de pós-treino que muitas vezes degradam a performance em tarefas de raciocínio longo.
Leia também

MIT Desenvolve Memória Espacial para Robôs: DAAAM Responde 'Onde Deixei Minhas Chaves?'
17 de junho de 2026
OpenAI Lança Deployment Simulation: Simulando Agentes de Código Antes do Lançamento
17 de junho de 2026
Governo Trump defende xAI em processo ambiental e alega que Grok é 'vital' para segurança nacional
16 de junho de 2026