Top 7 Modelos de Código que Você Pode Executar Localmente em 2026
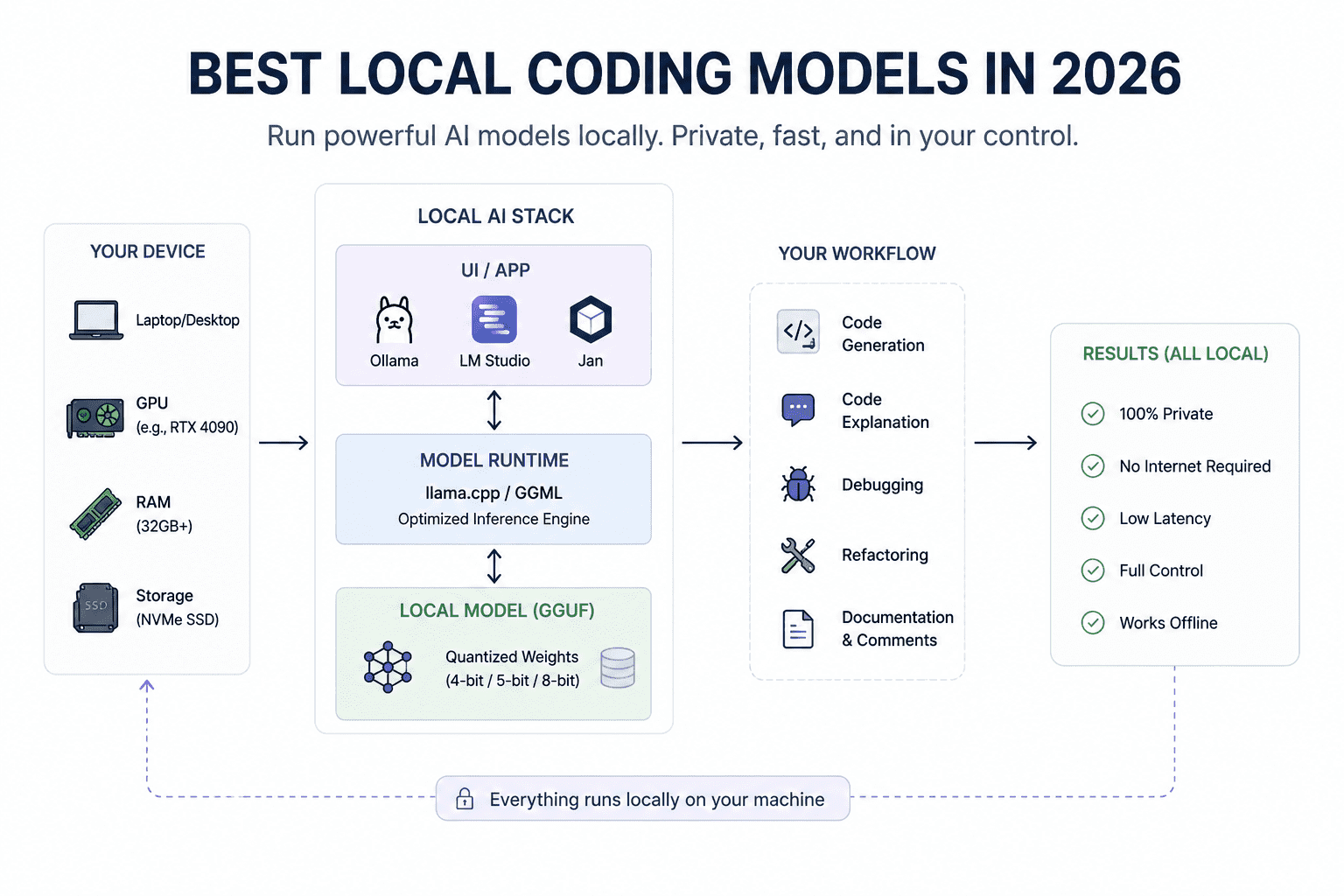
As coisas estão ficando sérias no mundo dos modelos de código locais. Acompanho essa nova onda de LLMs open-source e os lançamentos GGUF da comunidade que tornam possível rodar modelos poderosos em hardware de consumo. Já estamos num ponto em que alguns desses modelos rodam em GPUs como uma RTX 3090, geram código rápido o suficiente para serem úteis e realmente resolvem problemas reais de programação e workflows com agentes.
Se você quer um setup de codificação totalmente local e tem pelo menos 16 GB de VRAM, estes modelos podem ajudar você a se libertar da dependência exclusiva do Claude Code, Gemini ou outros assistentes hospedados na nuvem. O r/LocalLLaMA está cheio de desenvolvedores rodando agentes de código locais, testando modelos GGUF e conectando esses modelos a editores, terminais e assistentes de programação.
1. Qwen3.6 27B MTP
O Qwen3.6 27B MTP é facilmente um dos meus modelos de código locais favoritos no momento. Testei e explorei em diferentes setups, e ele parece o melhor equilíbrio entre tamanho, velocidade e capacidade real de codificação. A melhor parte é que, com as versões quantizadas GGUF, você consegue rodá-lo em hardware de consumo em vez de precisar de uma infraestrutura completa em nuvem.
Mesmo com uma GPU de 16 GB a 24 GB de VRAM, as versões de 4 bits tornam muito mais realista o uso local. A comunidade do Reddit já está cheia de pessoas testando o Qwen3.6 27B MTP para codificação com agentes, inferência rápida, setups com llama.cpp e servidores locais compatíveis com OpenAI.
Os modelos Qwen geralmente são fortes em codificação porque combinam raciocínio, seguimento de instruções, compreensão multilíngue, uso de ferramentas e suporte a contexto longo. Isso faz do Qwen3.6 27B MTP um modelo local versátil para assistentes de código, chat com repositórios, debugging, comandos shell e workflows com agentes.
2. Gemma 4 31B IT QAT
O Gemma 4 31B IT QAT é outro modelo que merece um lugar sério em qualquer setup de codificação local. Os modelos abertos Gemma do Google sempre foram bons para quem quer rodar modelos capazes localmente, e esta versão GGUF com treinamento consciente de quantização (QAT) torna tudo ainda mais prático.
Você obtém um modelo grande de 31B em formato quantizado de 4 bits, muito mais fácil de carregar em hardware de consumo, mantendo alta qualidade. O grande diferencial do Gemma 4 31B é que ele não é apenas um modelo de código — é também multimodal, o que significa que pode ajudar com screenshots, problemas de interface, diagramas, imagens de documentação e layouts de aplicações web, enquanto ainda é útil para geração de código, debugging e planejamento.
Os números oficiais de benchmark também são difíceis de ignorar, com fortes resultados em LiveCodeBench e Codeforces. Se você quer um modelo local que lide com codificação mais tarefas visuais de desenvolvimento, o Gemma 4 31B IT QAT é uma das melhores opções.
3. DiffusionGemma 26B A4B
O DiffusionGemma 26B A4B é um dos modelos mais novos e interessantes desta lista. Ele é poderoso, experimental e construído de forma diferente dos modelos de linguagem token-por-token tradicionais. Em vez de gerar texto da maneira autoregressiva padrão, ele usa uma abordagem de difusão em bloco, projetada para melhorar a velocidade de geração ao "denoising" blocos de tokens em paralelo.
É por isso que este modelo é empolgante para codificação local: parece o tipo de arquitetura que pode tornar assistentes locais muito mais rápidos, especialmente para geração de código, saídas estruturadas e tarefas de raciocínio rápido. O principal apelo é a eficiência — o DiffusionGemma tem cerca de 25B de parâmetros totais, mas apenas cerca de 3,8B de parâmetros ativos, então você obtém o benefício de um modelo maior estilo Mixture of Experts (MoE) sem pagar o custo total de inferência de um modelo denso de 26B.
4. Nemotron Cascade 2 30B A3B
O Nemotron Cascade 2 30B A3B é outro modelo que parece estranho no papel, mas faz muito sentido para codificação local. A NVIDIA construiu este modelo com uma arquitetura em cascata que usa cerca de 30B de parâmetros totais, mas apenas aproximadamente 3B de parâmetros ativos por token. O resultado é um modelo que oferece qualidade de modelo grande com velocidade de modelo pequeno.
Para desenvolvedores que buscam um assistente de código local rápido e responsivo, o Nemotron Cascade 2 é uma escolha sólida. Ele é particularmente bom em seguir instruções, gerar código limpo e lidar com tarefas de programação do mundo real sem consumir toda a sua VRAM. A arquitetura em cascata significa que você obtém respostas mais rápidas sem sacrificar muito a qualidade — ideal para uso diário em editores e terminais.
5. DeepSeek Coder V3
O DeepSeek Coder V3 continua a impressionar como um dos modelos de código especializados mais fortes disponíveis. Construído pela DeepSeek, este modelo foi treinado especificamente para tarefas de programação e consistentemente figura entre os melhores em benchmarks como HumanEval, MBPP e LiveCodeBench.
O que torna o DeepSeek Coder V3 particularmente útil para uso local são as versões quantizadas GGUF da comunidade, que permitem rodar o modelo completo ou variantes menores em hardware de consumo. Ele suporta dezenas de linguagens de programação, lida bem com contextos longos e é excelente para completar código, refatorar e gerar documentação.
6. CodeLlama 4 34B
O CodeLlama 4 34B da Meta é a mais recente iteração da linha CodeLlama, e representa um salto significativo em relação às versões anteriores. Treinado com mais dados de código e técnicas de fine-tuning melhoradas, ele oferece desempenho competitivo com modelos proprietários em muitas tarefas de programação.
As versões GGUF tornam este modelo de 34B acessível para GPUs de consumo de alta capacidade, especialmente nas quantizações de 4 e 5 bits. O CodeLlama 4 se destaca em preenchimento de código (infill), suporte a múltiplas linguagens e geração de código longo — útil para projetos maiores onde você precisa de contexto amplo.
7. StarCoder 3 15B
O StarCoder 3 15B fecha a lista como uma opção mais leve, mas ainda muito capaz. Desenvolvido pelo BigCode Project, este modelo foi treinado em um conjunto massivo de código open-source e oferece excelente desempenho para seu tamanho. Com apenas 15B de parâmetros, ele roda confortavelmente até em GPUs com 12-16 GB de VRAM.
O StarCoder 3 suporta mais de 80 linguagens de programação, lida bem com múltiplos arquivos e oferece preenchimento de contexto longo. É uma excelente porta de entrada para quem quer começar com modelos de código locais sem investir em hardware caro, e ainda assim obter resultados profissionais.
Conclusão
O ecossistema de modelos de código locais nunca esteve tão vibrante. De pesos pesados como Qwen3.6 27B e Gemma 4 31B a opções eficientes como StarCoder 3 15B, há um modelo local para cada necessidade e orçamento de hardware. O melhor de tudo: a comunidade open-source continua lançando versões GGUF quantizadas que tornam esses modelos cada vez mais acessíveis.
Se você ainda não experimentou rodar um modelo de código localmente, 2026 é o ano para começar.
Leia também
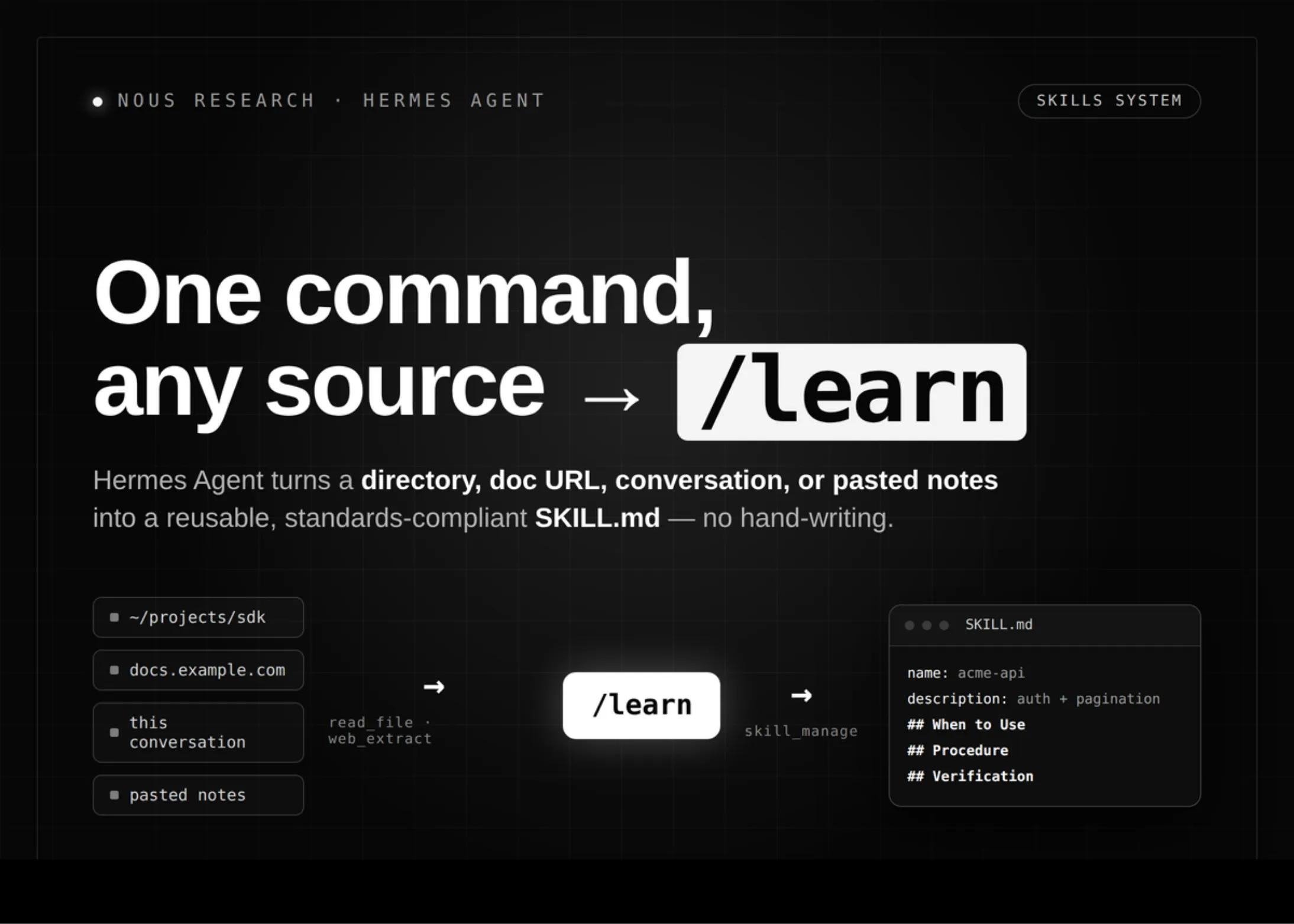
Nous Research adiciona /learn ao Hermes Agent: crie skills sem escrever SKILL.md
24 de junho de 2026
Datalab Lança Lift: Modelo de Visão Open-Source de 9B Extrai Dados Estruturados de PDFs com 90,2% de Precisão
23 de junho de 2026
Como criar loops poderosos com agentes de código no Claude Code e Codex
23 de junho de 2026